![]()
- AssetPublicity
- AuthorImExporter
- CategoryImExporter
- CategorySetImExporter
- CloudFrontInvalidatorForSiteSync
- ContentDataImExporter
- DuplicateEntry
- EntryImExporter
- GetLock
- MultiRebuilder
- PremiumOpenSearch
- PremiumSearch
- ReplaceableVersion
- RevisionDiff
- safepreview
- SitemapNavigator
- SiteSync
- SiteValidator
- WCAG
- WebsiteImExporter
- Workflow
PremiumOpenSearch
Amazon OpenSearch Service を用いた全文検索(旧称 Amazon Elasticsearch Service)
このプラグインは、検索エンジン「Amazon OpenSearch Service」を利用しHTML、PDFやオフィス系ドキュメントの検索を実現する事ができます。
PremiumSearch、PremiumOpenSearch はWEBサーバー(公開)とCMSサーバー(非公開)を SiteSync プラグインでファイル同期させるセキュアな運用・サーバー構成に適したサイト内検索を実現させるために制作しております。
このプラグインは PremiumSearch の後継にあたるものです。PremiumSearch で利用した検索エンジン Elasticsearch はバージョン 7.10.2以降はライセンス形態が変更されたため、 Amazon OpenSearch Service へ変更し、機能を追加・改修したプラグインです。
- Movable Type クラウド版ではご利用できません。
- PremiumSearchも利用は可能ですがPremiumOpenSearchと同時に利用することはできません、プラグイン設定でいずれかを無効に設定してください。
- デフォルトの設定ではいずれも無効となっております。
プラグインの特徴
- Amazon OpenSearch Serviceを利用したインデックス型全文検索が可能です。
- PDFやOfficeドキュメントの検索が可能です。
- DocumentType毎の絞り込みやディレクトリ単位での絞り込みが可能です。
- DataAPIを用いているため、開発者による柔軟なカスタマイズが可能です。
- [NEW] 検索モードを完全一致と部分一致に切り替えが出来るようになりました。
- [NEW] コマンドを打たずにMTの管理画面よりクロールが出来るようになりました。
- [NEW] ロールの権限でクロールを開始できる権限を付与できるようになりました。
- [NEW] サイト・子サイトのプラグイン設定画面「設定値を継承する」ことが出来るようになりました。
- [NEW] 検索結果ページに必要なモジュールが、システムのテンプレートモジュールにインストールされるようになりました。
- プラグインが有効になっている必要があります。
- DataAPIが利用出来る必要があります。
- Amazon OpenSearch Serviceサーバーの設定が別途必要となります。
- 動作検証は Amazon OpenSearch Service で行っております。
- Amazon OpenSearch Service に関してはサポート対象外となります。
- Windowsサーバーでの動作検証は現状未実施となりサポート対象外となります。
- 設定完了後のサーバー重複(本番環境を複製し検証環境を作成など)はご注意ください。検索インデックスに影響が出る場合がございますので、サーバーを複製する場合はクローラーの停止など対応をおこなってください。
サーバー要件
- Amazon OpenSearch Service
Amazon OpenSearch 2.5で開発・動作確認しています。
CMS(ステージング)サーバー
- Linux、Solaris / Unix、BSD、Mac OS X を推奨
- Perl 5.16.x 以上
- IO::Socket::SSL 2.009以上
- List::Util 1.55 以上
- Socket 2.030以上
ネットワーク要件
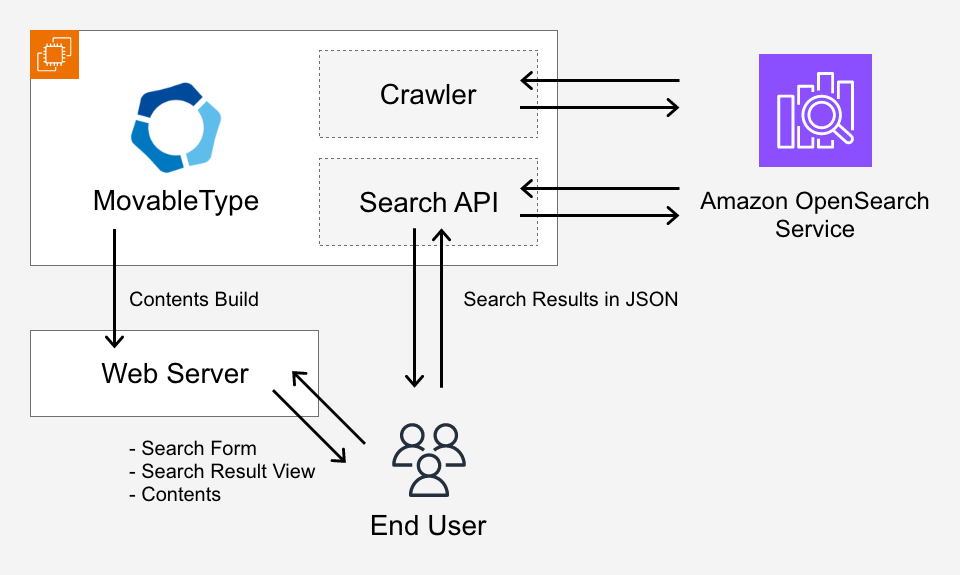
- CMSサーバーから検索サーバーへのHTTP接続許可が必要となります。
- CMSサーバーと公開サーバーが分離している場合には、CMSサーバーから公開サーバーへのHTTP接続許可が必要となります。
- エンドユーザーからCMSサーバーのDataAPIへの接続許可が必要となります。
プラグインの設定
プラグイン設定はシステム、サイト、子サイト単位で可能です。サイトダッシュボードのメニューから、[設定]>[プラグイン]をクリックし、プラグインの管理画面に遷移します。一覧の[PremiumOpenSearch]をクリックして[設定]タブをクリックすると、プラグインの設定画面が表示されます。
通常の運用ではシステムで設定をしましょう。サイト、子サイトではシステムの設定を継承されます。
デフォルト値:継承する
プラグイン設定:Open Search
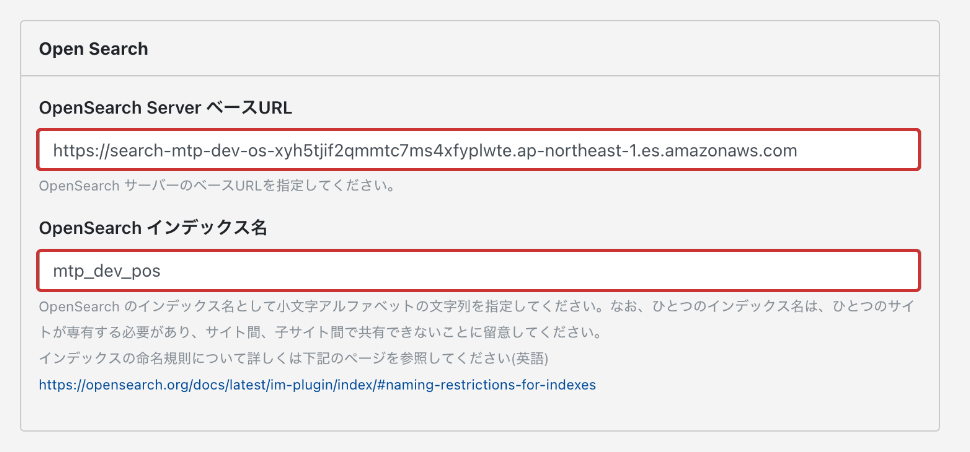
| フィールド名 | 必須 | 内容 |
|---|---|---|
|
OpenSearch Server ベースURL |
◯ |
OpenSearch サーバーのベースURLを設定してください。 例:https://search-mtp-dev-os-xyh5tf2qmmtcs4xfyplwte.ap-northeast-1.es.amazonaws.com
|
|
ElasticSearch インデックス名 |
◯ |
ElasticSearch のインデックス名を指定します。 例:my_site
インデックスの命名規則について詳しくは下記のページを参照してください |
プラグイン設定:クローラー
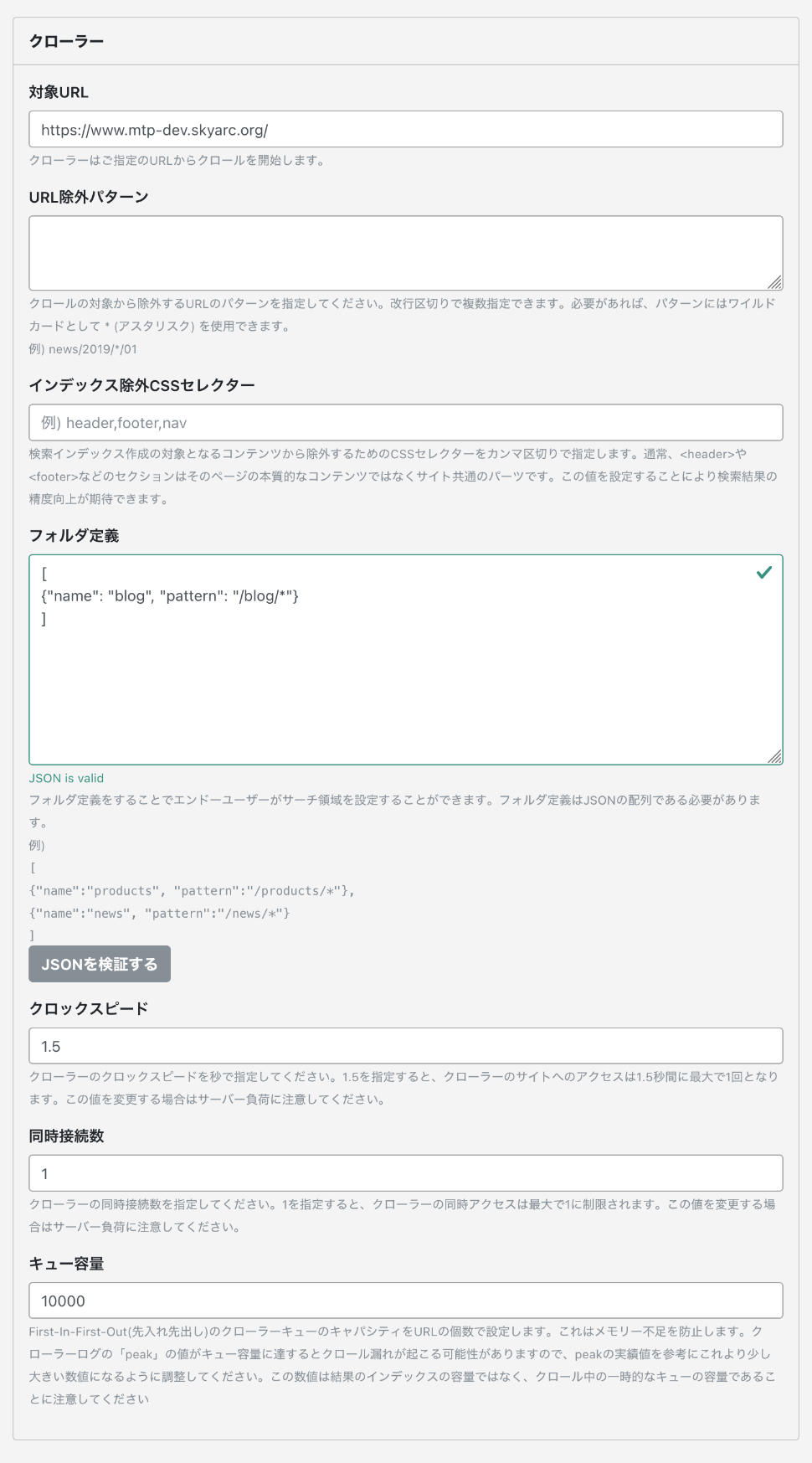
| フィールド名 | 必須 | 内容 |
|---|---|---|
|
対象URL |
◯ |
クローラーがクロールするURLを指定します。 例:https://www.skyarc.co.jp/
クローラーはご指定のURLからクロールを開始します。公開サーバーが分離している場合には、CMSサーバーから公開サーバーへのHTTP接続許可が必要となります。サイト・子サイトは対象URL以下に自動的にディレクトリパスが挿入されます。継承設定をしている場合でも同様にディレクトリパスが挿入されます。 |
|
URL除外パターン |
クロールの対象から除外するURLのパターンを指定してください。改行区切りで複数指定できます。 パターンにはワイルドカードとして * (アスタリスク) を使用できます。 例:news/2019/*/01 |
|
|
インデックス除外CSSセレクター |
検索インデックス作成の対象となるコンテンツから除外するための セレクターをカンマ区切りで指定します。 通常、<header>や<footer>などのセクションはそのページの本質的なコンテンツではなくサイト共通のパーツです。この値を設定することにより検索結果の精度向上が期待できます。 例:header,footer,nav
検索の精度を上げるためにヘッダーやフッターなどは除外しましょう |
|
|
フォルダ定義 |
フォルダ定義をすることで検索結果画面上にて指定フォルダによる絞り込み検索が可能になります。 フォルダ定義はJSONの配列である必要があります。 例:[
記述に問題ない場合は緑枠で表示されます、エラーがある場合は赤枠で表示されます。 |
|
|
クロックスピード |
◯ |
クローラーのクロックスピードを秒で指定してください。1.5を指定すると、クローラーのサイトへのアクセスは1.5秒間に最大で1回となります。 サーバー負荷を見てご調整頂くか、クローラー実行を夜間や朝方等のアクセスが少ない時間に実施ください。 初期値:1.5 |
|
同時接続数 |
◯ |
クローラーの同時接続数を指定してください。 1を指定すると、クローラーの同時アクセスは最大で1に制限されます。 変更する場合はサーバー負荷に注意してください。 初期値:1 |
|
キュー容量 |
◯ |
First-In-First-Out(先入れ先出し)のクローラーキューのキャパシティをURLの個数で設定します。これはメモリー不足を防止します。この数値は結果のインデックスの容量ではなく、クロール中の一時的なキューの容量であることに注意してください。 クローラーログの「ピーク」の値がキュー容量に達するとクロール漏れが起こる可能性がありますので、ピークの実績値を参考にこれより少し大きい数値になるように調整してください。 初期値:10000 |
プラグイン設定:検索

| フィールド名 | 必須 | 内容 |
|---|---|---|
|
デフォルトの検索結果件数 |
◯ |
検索結果の1ページに表示する件数のデフォルト値を設定してください。 ユーザはURLの「s」パラメータを指定することで「最大の検索結果件数」を上限としてサイズを変更できることに留意してください。 パラメータについては後述のAPIリファレンスを参照ください。 初期値:10 |
|
最大の検索結果件数 |
◯ |
検索結果の1ページに表示する件数の最大値を設定してください。この値を増やす場合はサーバー負荷に注意してください。 初期値:20 |
|
検索タイプ |
◯ |
検索の動作を設定します。入力した検索ワードが全て含まれるのが完全一致です。 初期値:部分一致
部分一致検索について
完全一致検索について
|
|
検索スコア |
◯ |
部分一致検索の場合にヒットする最小スコアを設定します。検索結果が想定よりも多くヒットしすぎるなどの場合に上方調整します。 初期値:1 |
クローラーの実行
クローラーの手動実行(システム)
Movabletype の管理画面からクロール実行を予約できます。以下の画像はシステムの管理者権限の管理画面です。
システム管理者のみクロールする対象のサイト(子サイト)を選択し実行できます。
手動で実行する場合でも cron などの定期実行の設定は必要になります。
手動実行の際、depth 指定は、-1 となります。
例:5分間隔
*/5 * * * * ./plugins/PremiumOpenSearch/tools/run_scheduled_crawl.pl
実行ボタンをクリックすることにより、クローリングタスクが登録されます。
その後、本cronが実行されたタイミングで、登録されたクローリングタスクが処理され、サイトのクローリングが開始されます。
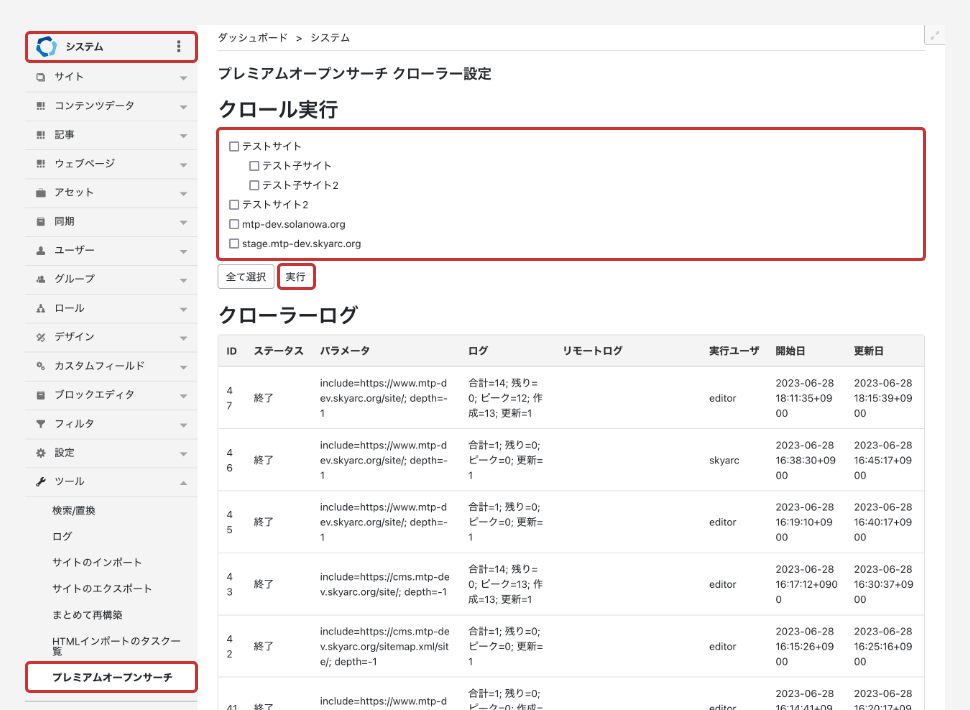
手動で実行する場合は以前のインデックスは削除され、新たに作成されます。
クローラーの手動実行(編集者)
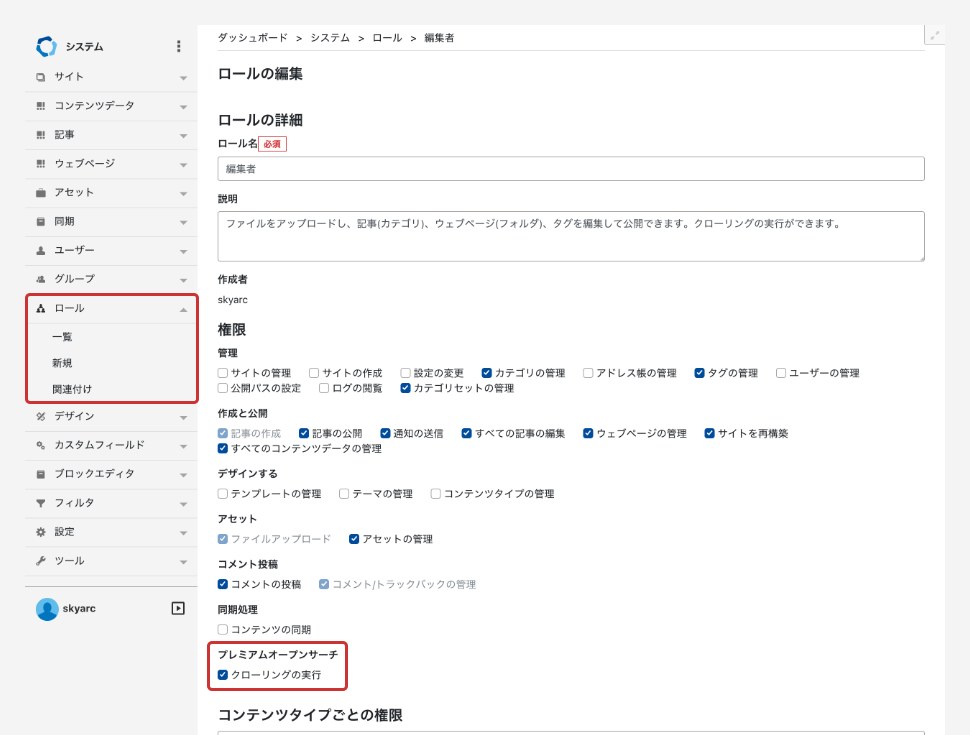
システム管理者ではないユーザーにクロールを実行させるには、ロールから[クローリングの実行]の権限を割り当てる必要があります。[クローリングの実行]権限を割り当てるにはシステム管理者の権限が必要です。
手動で実行する場合でも cron などの定期実行の設定は必要になります。
手動実行の際、depth 指定は、-1 となります。
例:5分間隔
*/5 * * * * ./plugins/PremiumOpenSearch/tools/run_scheduled_crawl.pl
実行ボタンをクリックすることにより、クローリングタスクが登録されます。
その後、本cronが実行されたタイミングで、登録されたクローリングタスクが処理され、サイトのクローリングが開始されます。
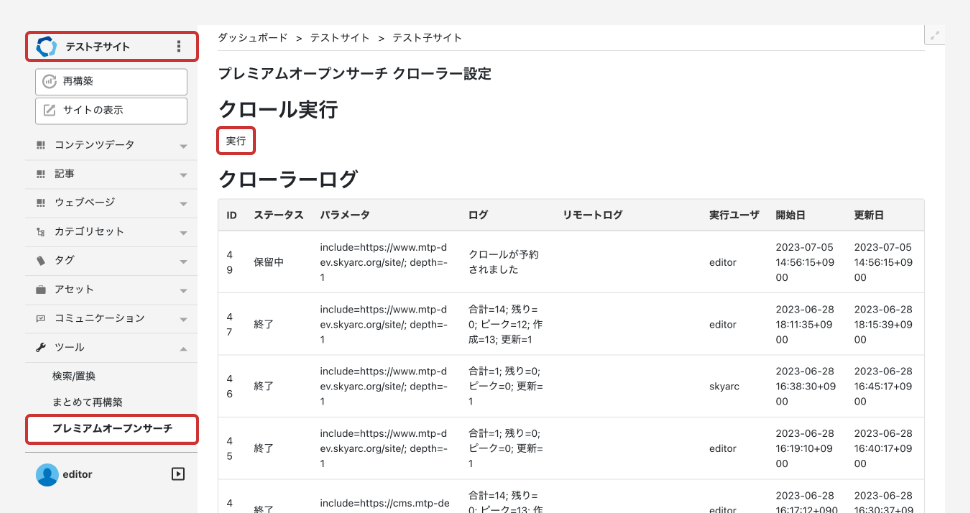
サイト、子サイト毎にクロールをさせる場合は、サイト、子サイト毎にプラグイン設定をしてください。初期値はシステムの設定が継承されます。
管理者権限がなくてもロール単位で権限を付与することができます。権限を付与されている場合はクロールを実行することができます。
サイトでクロールを実行する場合、子サイトがあれば合わせてクロールされます。子サイトをクロールされたくない場合はフォルダの除外設定やロールや権限を細分化してください。
クローラーのログ
クローラーの実行ログを確認することが可能です。実行ログはサイトメニューの[ツール] > [プレミアムオープンサーチ]より確認可能です。
インデックス(検索エンジンに記録されたWebサイト情報)の削除についてはクロール開始時刻より古いインデックスを全て削除しております。
検索結果画面の実装
MovableType Premium をインストールすると以下テンプレートがシステムのテンプレートモジュール / ウィジェットテンプレートにインストールされます。
テンプレートを元にオリジナルの検索結果画面も実装できます。インストールされたテンプレートをそのまま改変しても構いません。テンプレートを戻したい場合は図:Aより初期化が可能です。
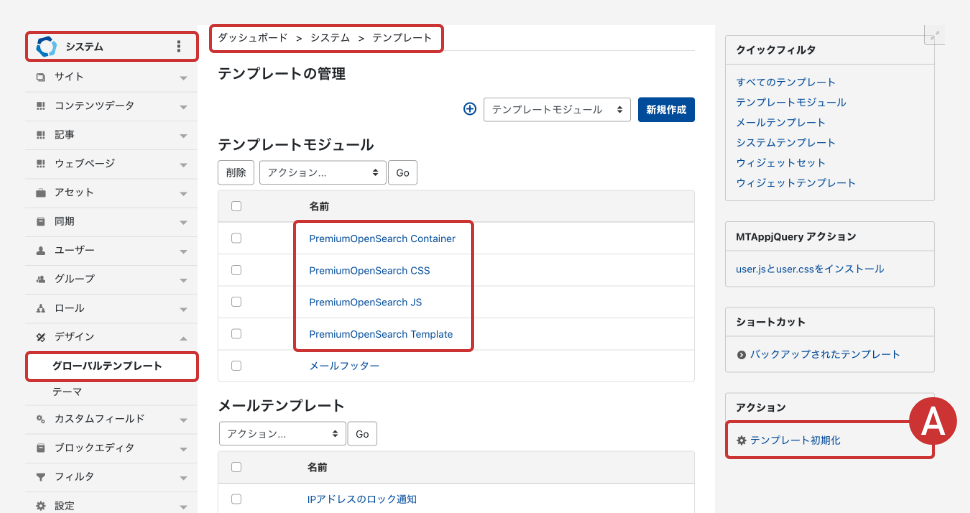
- PremiumOpenSearch Container
- PremiumOpenSearch CSS
- PremiumOpenSearch JS
- PremiumOpenSearch Template
- PremiumOpenSearch Widget(ウィジェットテンプレート)
検索結果画面の実装例
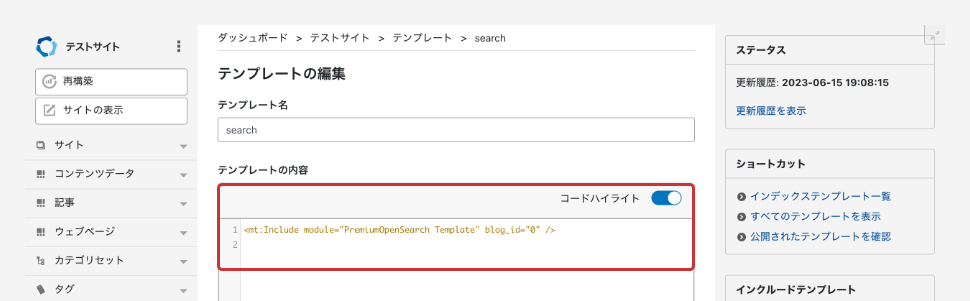
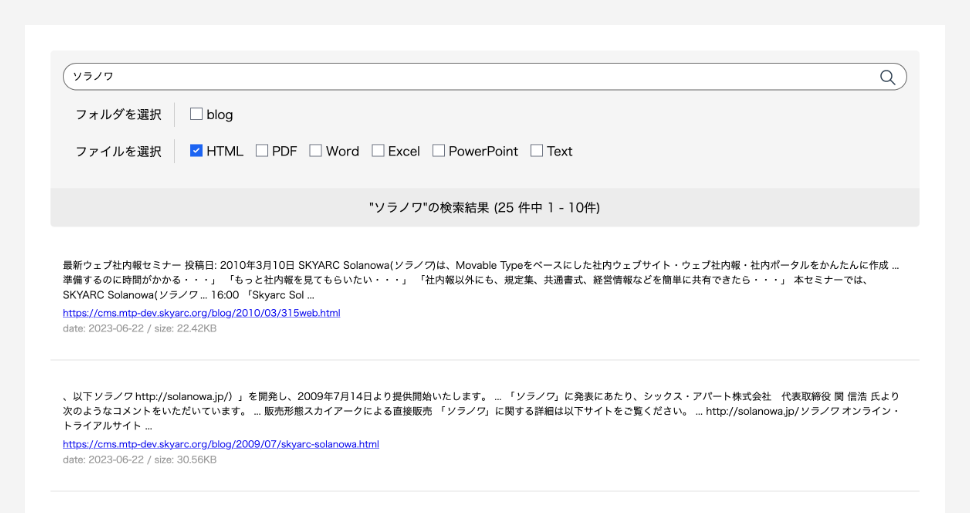
デフォルトのテンプレートでは以下のような検索結果画面が実装できます。インデックステンプレートに <mt:Include module="PremiumOpenSearch Template" blog_id="0" />と記載しお試しください。
プラグイン
- AssetPublicityアセットの適時公開
- AuthorImExporterユーザーを一括インポート・エクスポート
- CategoryImExporterカテゴリ・フォルダを一括インポート・エクスポート
- CategorySetImExporterカテゴリセットを一括インポート・エクスポート
- CloudFrontInvalidatorForSiteSyncSiteSync連動CloudFrontキャッシュ削除
- ContentDataImExporterコンテンツデータを一括インポート・エクスポート
- DuplicateEntry記事・ウェブページ・コンテンツデータを複製または移動
- EntryImExporter記事・ウェブページを一括インポート・エクスポート
- GetLock編集画面をロックする
- MultiRebuilderサイト・子サイトの一括再構築
- PremiumOpenSearchAmazon OpenSearch Service を用いた全文検索(旧称 Amazon Elasticsearch Service)
- PremiumSearchElasticsearchを用いた全文検索
- ReplaceableVersion差し替え用ページ(リビジョン)の作成
- RevisionDiff編集履歴から差分を比較する
- safepreviewプレビュー画面を安全に生成
- SitemapNavigatorフォルダやコンテンツタイプの階層(ツリー)メニュー
- SiteSyncステージングサーバーと公開サーバー間でコンテンツを同期する
- SiteValidatorバリデーションチェックを利用する
- WCAG「WCAG2.0(JIS X 8341)」準拠のアクセシビリティチェック
- WebsiteImExporterHTML・アセットインポート
- Workflow多段階承認フロー
![]()